
On November fourth, we announced Azure Synapse Analytics, the next evolution of Azure SQL Data Warehouse. Azure Synapse is a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It gives you the freedom to query data on your terms, using either serverless on-demand or provisioned resources—at scale. Azure Synapse brings these two worlds together with a unified experience to ingest, prepare, manage, and serve data for immediate business intelligence and machine learning needs.
With Azure Synapse, data professionals can query both relational and non-relational data using the familiar SQL language. This can be done using either serverless on-demand queries for data exploration and ad hoc analysis or provisioned resources for your most demanding data warehousing needs. A single service for any workload.
In fact, it’s the first and only analytics system to have run all the TPC-H queries at petabyte-scale. For current SQL Data Warehouse customers, you can continue running your existing data warehouse workloads in production today with Azure Synapse and will automatically benefit from the new preview capabilities when they become generally available. You can sign up to preview new features like serverless on-demand query, Azure Synapse studio, and Apache Spark™ integration.

Taking SQL beyond data warehousing
A cloud native, distributed SQL processing engine is at the foundation of Azure Synapse and is what enables the service to support the most demanding enterprise data warehousing workloads. This week at Ignite we introduced a number of exciting features to make data warehousing with Azure Synapse easier and allow organizations to use SQL for a broader set of analytics use cases.
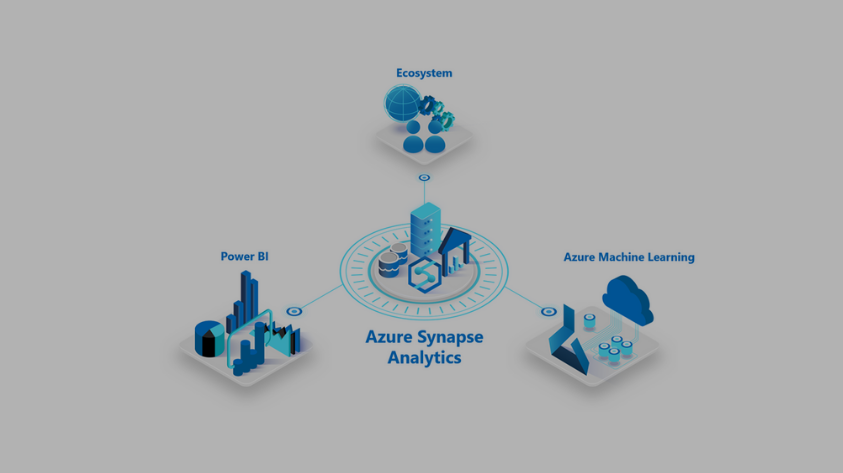
Unlock powerful insights faster from all data
Azure Synapse deeply integrates with Power BI and Azure Machine Learning to drive insights for all users, from data scientists coding with statistics to the business user with Power BI. And to make all types of analytics possible, we’re announcing native and built-in prediction support, as well as runtime level improvements to how Azure Synapse handles streaming data, parquet files, and Polybase. Let’s dive into more detail:
- With the native PREDICT statement, you can score machine learning models within your data warehouse—avoiding the need for large and complex data movement. The PREDICT function (available in preview) relies on open model framework and takes user data as input to generate predictions. Users can convert existing models trained in Azure Machine Learning, Apache Spark™, or other frameworks into an internal format representation without having to start from scratch, accelerating time to insight.

- We’ve enabled direct streaming ingestion support and ability to execute analytical queries over streaming data. Capabilities such as: joins across multiple streaming inputs, aggregations within one or more streaming inputs, transform semi-structured data and multiple temporal windows are all supported directly in your data warehousing environment (available in preview). For streaming ingestion, customers can integrate with Event Hubs (including Event Hubs for Kafka) and IoT Hubs.
- We’re also removing the barrier that inhibits securely and easily sharing data inside or outside your organization with Azure Data Share integration for sharing both data lake and data warehouse data.
- By using new ParquetDirect technology, we are making interactive queries over the data lake a reality (in preview). It’s designed to access Parquet files with native support directly built into the engine. Through improved data scan rates, intelligent data caching and columnstore batch processing, we’ve improved Polybase execution by over 13x.

Workload isolation
To support customers as they democratize their data warehouses, we are announcing new features for intelligent workload management. The new Workload Isolation functionality allows you to manage the execution of heterogeneous workloads while providing flexibility and control over data warehouse resources. This leads to improved execution predictability and enhances the ability to satisfy predefined SLAs.

COPY statement
Analyzing petabyte-scale data requires ingesting petabyte-scale data. To streamline the data ingestion process, we are introducing a simple and flexible COPY statement. With only one command, Azure Synapse now enables data to be seamlessly ingested into a data warehouse in a fast and secure manner.
This new COPY statement enables using a single T-SQL statement to load data, parse standard CSV files, and more.
Safe keeping for data with unmatched security
Azure has the most advanced security and privacy features in the market. These features are built into the fabric of Azure Synapse, such as automated threat detection and always-on data encryption. And for fine-grained access control businesses can ensure data stays safe and private using column-level security, native row-level security, and dynamic data masking (now generally available) to automatically protect sensitive data in real-time.
To further enhance security and privacy, we are introducing Azure Private Link. It provides a secure and scalable way to consume deployed resources from your own Azure Virtual Network (VNet). A secure connection is established using a consent-based call flow. Once established, all data that flows between Azure Synapse and service consumers is isolated from the internet and stays on the Microsoft network. There is no longer a need for gateways, network addresses translation (NAT) devices, or public IP addresses to communicate with the service.

Get started today
Businesses can continue running their existing data warehouse workloads in production today with generally available features on Azure Synapse.